Databases
In this tutorial, we are going to discuss about databases, another essential system design concept. Choosing the right database for any system design is always an important decision. As we know that the databases are an important part of the system and it also plays a major role to achieve speed, scalability, and consistency in the systems.
What is a Database?
A database is a structured collection of data organized in such a way that it can be easily accessed, managed, and updated.
Databases are responsible for the storage and retrieval of data from a data application. They are an essential part as all the information is stored inside them so getting their design principle understanding is crucial as with rising in big data several activities that involve our interaction with databases.
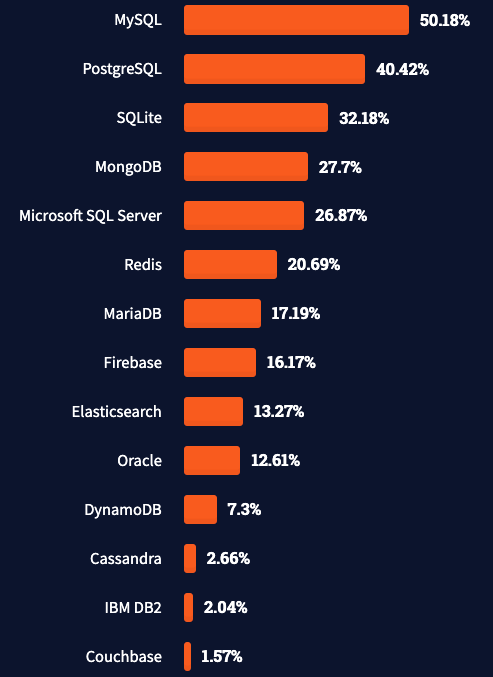
Here is the list of some popular databases based on Stack Overflow Developer Survey 2021.
Types of Databases

1. Relational databases
Relational databases store data in tables consisting of rows and columns, with relationships defined between them. They have predefined schemas, just like phone books that store numbers and addresses. They use Structured Query Language (SQL) for querying and managing data. Examples include MySQL, PostgreSQL, Oracle Database, Microsoft SQL Server, and SQLite.
2. Non-relational databases
Non-relational databases, also known as NoSQL (Not Only SQL) databases, are a category of databases that diverge from the traditional relational database model.
Non-relational databases, or no-SQL databases, are unstructured. They have a dynamic schema, like file folders that store information from someone’s address and number to their Facebook likes and online shopping preferences. There are different types of NoSQL. The most common types include:
- Key-value stores, such as Redis and DynamoDB
- Document databases, such as MongoDB and CouchDB
- Wide-column databases, such as Cassandra and HBase
- Graph databases, such as Neo4J and InfiniteGraph
How to choose a database?
Databases are a basic foundation of software development. They serve many different purposes for building projects of all sizes and types. When choosing your database structure, it’s important to factor in speed, reliability, and accuracy. We have relational databases that can guarantee data validity, and we have non-relational databases that can guarantee eventual consistency. When choosing your database structure, it’s important to factor in database fundamentals, such as:
- ACID
- BASE
- SQL joins
- Normalization
- Persistence
- Etc.
Database decisions are an important part of system design interviews, so it’s important to get comfortable with making decisions based on unique use cases. The database you choose will depend upon your project.
CAP Theorem
Let’s take a detailed look at the three distributed system characteristics to which the CAP theorem refers.
Consistency
Consistency means that all clients see the same data at the same time, no matter which node they connect to. For this to happen, whenever data is written to one node, it must be instantly forwarded or replicated to all the other nodes in the system before the write is deemed ‘successful.’
Availability
Availability means that any client making a request for data gets a response, even if one or more nodes are down. Another way to state this—all working nodes in the distributed system return a valid response for any request, without exception.
Partition tolerance
A partition is a communications break within a distributed system—a lost or temporarily delayed connection between two nodes. Partition tolerance means that the cluster must continue to work despite any number of communication breakdowns between nodes in the system.
Transactions
A transaction is a series of database operations that are considered to be a “single unit of work”. The operations in a transaction either all succeed, or they all fail. In this way, the notion of a transaction supports data integrity when part of a system fails. This is formalized in the “ACID” properties:
- Atomicity – Atomicity ensures that a group of operations are treated as a single unit of work. If any of these operations fail, entire transaction will fail. This is important in transactions as it ensures that all or nothing is achieved.
- Consistency – In database applications, Before the Transaction and After the Transaction Database state must be in stable.
- Isolation – If we run more than one Transaction on a single Data item then that Transactions are called as “Concurrent Transactions”. In Transactions Concurrency, one transaction execution must not give effect to another Transaction, this rule is called as “Isolation” property.
- Durability – After committing the Transaction, if any failures are coming like Power failure, OS failure etc. after getting the System if we open the transaction then the modifications which we performed during the transaction must be preserved.
Not all databases choose to support ACID transactions, usually because they are prioritizing other optimizations that are hard or theoretically impossible to implement together. Usually relational databases do support ACID transactions, and non-relational databases don’t.
Schemas
The role of a schema is to define the shape of a data structure, and specify what kinds of data can go where. In databases specifically, a schema can specify database-level structures like tables and indexes, and also data-level constraints like field types (string, boolean, reference, etc.)
Database schemas are abstract designs that represent the storage of the data in a database. They describe the organization of data and the relationships between tables in a given database. You plan database schemas in advance so you know what components are necessary and how they’ll connect to each other. A database schema doesn’t hold data but instead describes the shape of the data and how it relates to other tables or models. An entry in a database is an instance of a database schema.
There are two main database schema types that define different parts of the schema: logical and physical.

The logical schema defines the structure of the data itself and the relationships between the various attributes, tables, and entries. However, the physical schema defines how the data is stored and managed on the physical hard disk of the devices the database is running on.
The physical schema is a little different and is largely dependent on the structure of the logical schema. The physical database schema represents how data is stored on the device hard disk. This is the actual code that will be used to create the structure of your database which includes any tables and how they relate to each other.
Consider a simple database for managing customer information:
- Logical Schema: It might include tables such as Customer, Order, and Product. The Customer table might have columns like customer_id, customer_name, customer_email, etc. Relationships between tables (e.g., a customer can place multiple orders) are defined through keys like primary and foreign keys.
- Physical Schema: Underlying, the Customer table might be stored as a B-tree index on disk, with data organized in pages, and possibly indexed on the customer_id column for efficient retrieval. The database management system may decide to use certain disk allocation strategies, caching mechanisms, or indexing techniques to optimize performance.
Database queries
A database query is a request to access data from a database to manipulate or retrieve it. It’s most closely associated with CRUD operations. Database queries allow us to perform logic with the information we get in response to the query. There are many different approaches to queries, from using query strings to writing with a query language, to using a QBE (Query by Example) like GraphQL.
Scaling
It is more important than ever to be able to implement databases in distributed clusters as dataset sizes continue to grow. Different databases are better and worse at scaling because of the features they provide. There are two kinds of scaling:
- Vertical Scaling: adding compute (CPU) and memory (RAM, Disk, SSD) resources to a single computer.
- Horizontal Scaling: adding more computers to a cluster
Vertical scaling is fairly straightforward, but has much lower overall memory capacity. Horizontal scaling on the other hand has much higher overall compute and storage capacity, and can be sized dynamically without downtime. The big drawback is that relational databases, the most popular database model, struggle to scale horizontally.
SQL vs NoSQL
While designing any application, one needs to be clear about the type of storage according to the system requirements. If system is distributed in nature and scalability is essential, then NoSQL databases are the best choice to go with. No-SQL databases are also preferred when amount of data is huge.
Simultaneously, SQL databases are favorable when data structure is more important. It is generally preferred when queries are complex and databases require fewer updates. However, there is always a trade-off when choosing between NoSQL vs SQL database. Sometimes, according to business requirements, a Polyglot architecture comprising both SQL and NoSQL databases is used to ensure application performance.
Database sharding and partitioning
When sharding a database, you make partitions of data so that the data is divided into various smaller, distinct chunks called shards. Each shard could be a table, a Postgres schema, or a different physical database held on a separate database server instance. Some data within the database remains present in all shards, while some only appear in single shards. These two situations can be referred to as vertical sharding and horizontal sharding. Let’s take a look at a visual

To shard your data, you need to determine a sharding key to partition your data. The sharding key can either be an indexed field or indexed compound fields that exist in every document in the collection. There’s no general rule for determining your sharding key. It all depends on your application.
Sharding allows your application to make fewer queries. When it receives a request, the application knows where to route the request. This means that it has to look through less data rather than going through the entire database. Sharding improves your application’s overall performance and scalability.
Data partitioning is a technique that breaks up a big database into smaller parts. This process allows us to split our database across multiple machines to improve our application’s performance, availability, load balancing, and manageability.
Database indexing
Database indexing allows you to make it faster and easier to search through your tables and find the rows or columns that you want. Indexes can be created using one or more columns of a database table, providing the basis for both rapid random lookups and efficient access of ordered information. While indexes dramatically speed up data retrieval, they typically slow down data insertion and updates because of their size.
That’s all about databases in system design. If you have any queries or feedback, please write us at contact@waytoeasylearn.com. Enjoy learning, Enjoy system design..!!