In this tutorial, we’ll explore Availability — a foundational concept in System Design. If you’ve ever experienced a moment where an app wouldn’t load or a website became unresponsive, you’ve faced a real-world consequence of poor availability.
For example, in a recent global outage, YouTube was inaccessible for nearly an hour, disrupting content creators, viewers, and advertisers. Incidents like this raise critical questions:
- Why do systems become unavailable?
- How can we prevent such failures?
Let’s dive deep into what availability means, how it’s measured, and how to design systems that remain accessible even during failures.
In system design, Availability is a critical non-functional requirement that determines how accessible and operational your system is for users at any given time. In today’s digital world, where businesses rely on online services 24/7, even a few minutes of downtime can cause major disruptions, loss of revenue, and damage to brand reputation. In this tutorial, we’ll understand:
- Key strategies like redundancy, high availability, and fault tolerance.
- What is Availability?
- How is it measured?
- How do real companies like YouTube or Netflix achieve it?
📌 What is Availability?
Availability refers to the percentage of time a system remains up and accessible to users during a specific period. It ensures that a system can respond to user requests reliably, even during hardware failures or unexpected loads.
✅ Simple Definition: A system is available if it is up, responsive, and able to fulfill user requests when needed.
Example
If a user wants to access your system (like open a website, stream a video, or send a message), the system must respond and work as expected.
🔄 Real world example
Imagine your favorite coffee shop. It’s your go-to place to grab coffee on your way to work. If it’s open 6 days a week, it’s considered available 6 out of 7 days. But what if one day it’s closed unexpectedly? You’ll be forced to find another coffee shop, right?
In the world of system design, this idea of how often a system is available and functioning as expected is what we call Availability.
💡 Why Does Availability Matter?
Availability directly impacts:
- User trust and satisfaction
- Revenue generation
- Business continuity
- System reliability and resilience
For instance:
- 🛒 E-commerce: If Amazon is down during Black Friday, it loses millions in minutes.
- 📹 Streaming: If Netflix buffers or fails to load, users churn to competitors.
- 💰 Banking: Downtime can mean failed transactions and regulatory penalties.
- 🚑 Healthcare: Critical systems like patient monitoring must be available 100%.
📊 Real-World Examples
✈️ 1. Air Traffic Control Systems
- Need: Must work 24/7 with zero failure.
- Why: A minute of downtime can risk hundreds of lives.
- Solution: Use of redundant systems, automatic failovers, and real-time monitoring.
🎬 2. Netflix or Amazon Prime Video
- Need: High availability to ensure smooth video streaming.
- Solution: Use load balancers, redundant data centers, and global content delivery networks (CDNs).
🛒 3. E-Commerce Websites (e.g., Amazon, Flipkart)
- Need: System must stay up even during high-traffic sales.
- Solution: Use auto-scaling, distributed systems, and failover databases.
🎯 How is Availability Measured?
The availability of a system is measured as the percentage of a system’s uptime in a given time period or by dividing the total uptime by the total uptime and downtime in a given period of time.
Availability = Uptime ÷ (Uptime + Downtime)For example:
If a system is down for 1 hour in a 1,000-hour period:
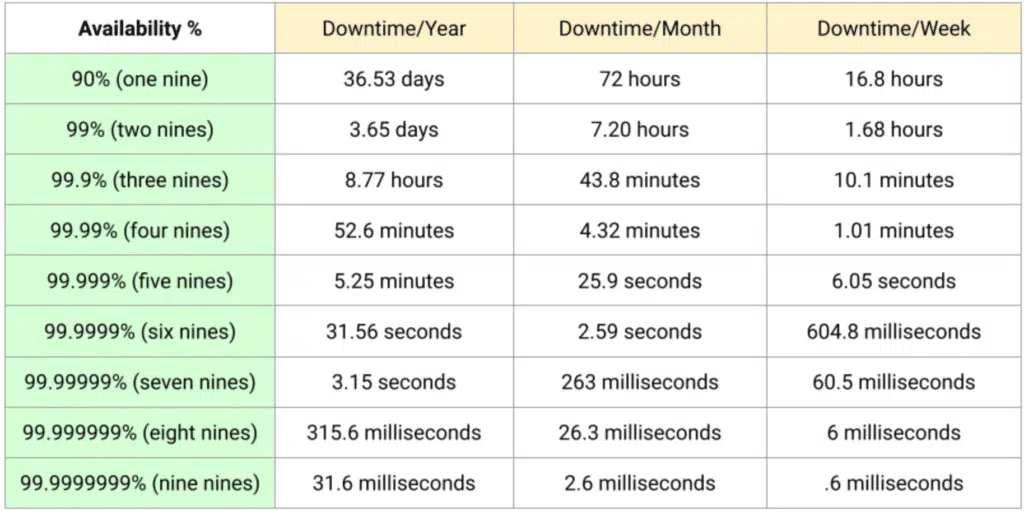
Availability = (999 ÷ 1000) × 100 = 99.9%🔢 The Nine’s of Availability (9s of Uptime)
The 9’s of Availability is a commonly used metric to assess system availability, where each nine represents a decimal point. For example, three nines of availability corresponds to 99.9% uptime. This measurement allows organizations to evaluate and optimize availability based on their specific requirements.
In high-demand applications, we usually measure availability in terms of Nines rather than percentages. If availability is 99.00 percent, it is said to have “2 nines” of availability, and if it is 99.9 percent, it is called “3 nines,” and so on. A system with 5 nines (i.e., 99.999%) of availability is said to have a Gold Standard of Availability. Let’s take a look at different Nines of Availability.
🔧 How to Achieve High Availability (HA)?
Achieving high availability is not accidental — it requires deliberate design choices. One of the most common strategies is redundancy: having backup components ready to take over when one fails.
🔁 1. Redundancy Models
🔹 Passive Redundancy:
- Backup components remain idle until a failure is detected.
- Example: A standby server takes over if the main server fails.
🔹 Active Redundancy:
- Multiple components work in parallel.
- If one fails, others instantly take over without interruption.
- Example: Two web servers behind a load balancer, both handling traffic concurrently.
🧠 Note: Redundancy improves availability, but must be paired with proper failure detection, monitoring, and automatic recovery mechanisms.
⚙️ 2. Additional High Availability Strategies
- Load Balancing: Distribute traffic evenly across servers to avoid overload.
- Health Checks: Regularly ping servers to detect failures quickly.
- Auto-scaling: Add new instances automatically when traffic increases.
- Disaster Recovery: Maintain backups and failover mechanisms across regions.
- Geographic Distribution: Use multiple data centers in different locations.
🌐 Types of Availability
1. High Availability (HA)
High availability means your system continues to function even if part of it fails.
🔧 Example:
Netflix has servers across multiple regions. If one region goes down, traffic is rerouted automatically.
2. Fault Tolerance
Fault-tolerant systems can handle failure gracefully without affecting the user.
⚙️ Example:
A plane engine system. Even if one engine fails, the other takes over. No crash.
3. Disaster Recovery
When something catastrophic happens, how quickly can you recover?
📁 Example:
If all servers crash, can you restore from backups? That’s disaster recovery.
🆚 Availability vs Fault Tolerance – What’s the Difference?
While they sound similar, Availability and Fault Tolerance serve different purposes:
| Feature | High Availability | Fault Tolerance |
|---|---|---|
| Goal | Minimize downtime | Eliminate single points of failure |
| Approach | Use redundant systems & failover | Use parallel systems that work together |
| Example | Cluster of web servers with failover | Aircraft systems running duplicate processors |
| Downtime Tolerance | Minimal, but non-zero | Ideally zero downtime |
| Cost & Complexity | Lower | Higher due to hardware & coordination |
💡 In short: High Availability allows for quick recovery from failure, while Fault Tolerance ensures no disruption even when failures occur.
🚦 Availability vs Reliability vs Durability
| Term | Description | Analogy |
|---|---|---|
| Availability | System is up and running | Coffee shop is open |
| Reliability | System works correctly without failure | Coffee tastes the same every time |
| Durability | Data is not lost over time | Loyalty card points never disappear |
🛠️ Design Patterns for High Availability
1. Active-Active Clustering
- All nodes are actively serving requests.
- Increases performance and availability.
2. Active-Passive Clustering
- One active node, one standby.
- If the active node fails, the passive takes over.
3. Quorum-Based Replication
- A majority (quorum) must agree before operations proceed.
- Ensures availability while maintaining consistency trade-offs.
📝 Summary
Availability is not just a metric, it’s a design principle. Building highly available systems means anticipating failures and engineering your system to recover quickly and serve users with minimal disruption.
Whether you’re building a payment gateway, a chat application, or a streaming service, Availability must be part of your design from day one.
📬 Have Questions or Feedback?
That’s everything about Availability in system design. If you have any questions, feel free to reach out at contact@waytoeasylearn.com.
Enjoy learning. Enjoy System Design Tutorials! 🚀