Cassandra Consistency Levels
In this tutorial, we are going to discuss about the Cassandra Consistency Levels. In Cassandra, consistency levels are settings that define how many replicas must respond to a read or write operation for the operation to be considered successful. They allow you to balance trade-offs between availability, latency, and consistency.
What are Cassandra’s consistency levels?
Cassandra consistency levels are defined as the minimum number of Cassandra nodes that must fulfill a read or write operation before the operation can be considered successful. Cassandra allows us to specify different consistency levels for read and write operations. Also, Cassandra has tunable consistency, i.e., we can increase or decrease the consistency levels for each request.
There is always a tradeoff between consistency and performance. A higher consistency level means that more nodes need to respond to a read or write query, giving the user more assurance that the values present on each replica are the same. Here’s a breakdown of some of the key consistency levels:
1. ANY
- Writes: Acknowledged as soon as one replica (even a hinted handoff) records the write. The write is guaranteed to be eventually propagated to all replicas.
- Consistency: Lowest; the write might not be immediately available to all replicas.
- Use Case: High availability is prioritized over immediate consistency.
2. ONE
- Reads/Writes: Requires a response from one replica.
- Consistency: Low; if that one replica has an outdated value, the client may read stale data.
- Use Case: When low latency and availability are prioritized over strong consistency.
3. TWO
- Reads/Writes: Requires responses from two replicas.
- Consistency: Moderate; better than ONE but still allows for potentially stale reads.
- Use Case: A balance between latency and consistency without the higher overhead of QUORUM.
4. THREE
- Reads/Writes: Requires responses from three replicas.
- Consistency: Stronger than ONE or TWO.
- Use Case: Provides stronger consistency but adds some latency and reduces availability compared to lower levels.
5. QUORUM
- Reads/Writes: Requires a majority of replicas (⌊(replication_factor / 2) + 1⌋) to respond.
- Consistency: Good consistency without full replica coordination; strong for typical read/write operations.
- Use Case: Commonly used for scenarios requiring a balance between latency, availability, and consistency.
6. LOCAL_QUORUM
- Reads/Writes: Requires a majority of replicas in the same data center.
- Consistency: Similar to QUORUM but optimized for single data center operations.
- Use Case: Multi-data center deployments where you want consistency within a local data center for faster reads and writes.
7. EACH_QUORUM
- Reads/Writes: Requires a quorum of replicas in each data center.
- Consistency: Stronger than LOCAL_QUORUM, ensures consistency across data centers.
- Use Case: When data consistency across data centers is critical for the application.
8. ALL
- Reads/Writes: Requires all replicas to respond.
- Consistency: Highest; all replicas must have the latest data, minimizing the chance of stale reads.
- Use Case: When absolute consistency is critical and can tolerate latency and reduced availability.
Choosing Consistency Levels
The best consistency level depends on the application’s requirements:
- Low Latency and High Availability: Levels like ONE or ANY.
- Stronger Consistency Guarantees: QUORUM, LOCAL_QUORUM, or ALL.
- Cross-Data Center Consistency: EACH_QUORUM if you need strong consistency across geographically distributed replicas.
Hinted handoff
Depending upon the consistency level, Cassandra can still serve write requests even when nodes are down. For example, if we have the replication factor of three and the client is writing with a quorum consistency level. This means that if one of the nodes is down, Cassandra can still write on the remaining two nodes to fulfill the consistency level, hence, making the write successful.
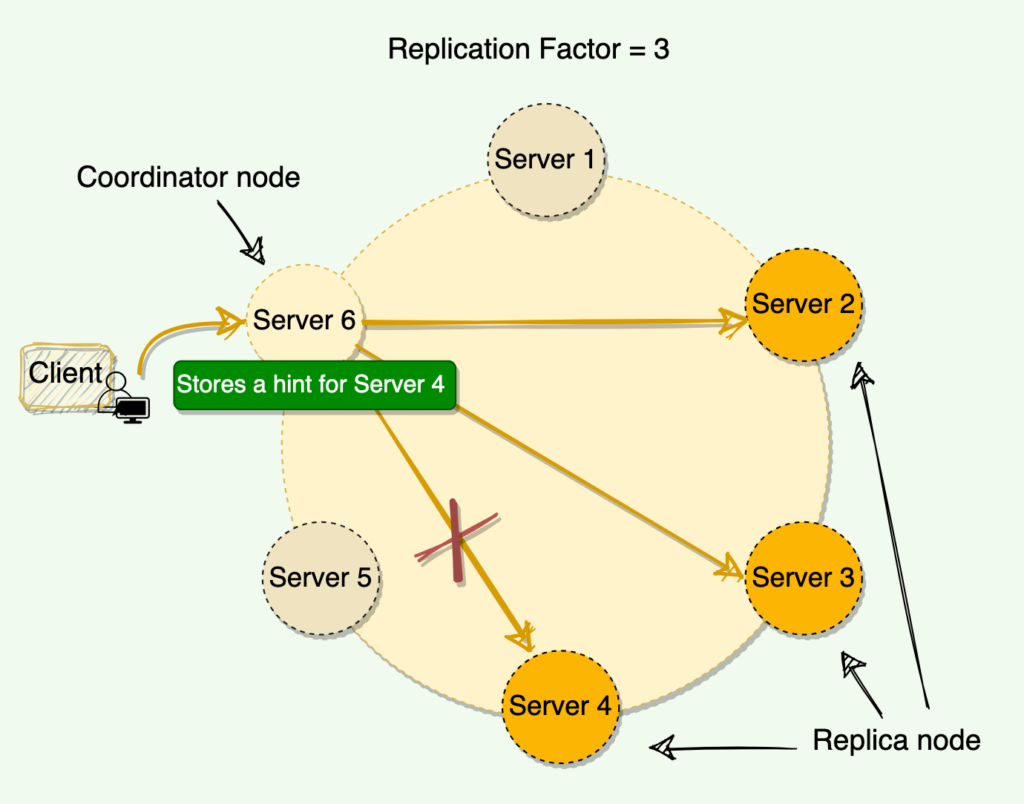
Now when the node which was down comes online again, how should we write data to it? Cassandra accomplishes this through hinted handoff.
When a node is down or does not respond to a write request, the coordinator node writes a hint in a text file on the local disk. This hint contains the data itself along with information about which node the data belongs to. When the coordinator node discovers from the Gossiper (will be discussed later) that a node for which it holds hints has recovered, it forwards the write requests for each hint to the target. Furthermore, each node every ten minutes checks to see if the failing node, for which it is holding any hints, has recovered.
With consistency level ‘Any,’ if all the replica nodes are down, the coordinator node will write the hints for all the nodes and report success to the client. However, this data will not reappear in any subsequent reads until one of the replica nodes comes back online, and the coordinator node successfully forwards the write requests to it. This is assuming that the coordinator node is up when the replica node comes back. This also means that we can lose our data if the coordinator node dies and never comes back. For this reason, we should avoid using the ‘Any’ consistency level.
If a node is offline for some time, the hints can build up considerably on other nodes. Now, when the failed node comes back online, other nodes tend to flood that node with write requests. This can cause issues on the node, as it is already trying to come back after a failure. To address this problem, Cassandra limits the storage of hints to a configurable time window. It is also possible to disable hinted handoff entirely.
Cassandra, by default, stores hints for three hours. After three hours, older hints will be removed, which means, if now the failed node recovers, it will have stale data. Cassandra can fix this stale data while serving a read request. Cassandra can issue a Read Repair when it sees stale data; we will go through this while discussing the read path.
One thing to remember: When the cluster cannot meet the consistency level specified by the client, Cassandra fails the write request and does not store a hint.
Read consistency levels
The consistency level for read queries specifies how many replica nodes must respond to a read request before returning the data. For example, for a read request with a consistency level of quorum and replication factor of three, the coordinator waits for successful replies from at least two nodes.
Cassandra has the same consistency levels for read operations as that of write operations except for Each_Quorum (because it is very expensive).
To achieve strong consistency in Cassandra: R + W > RF gives us strong consistency. In this equation, R, W, and RF are the read replica count, the write replica count, and the replication factor, respectively. All client reads will see the most recent write in this scenario, and we will have strong consistency.
Snitch: The Snitch is an application that determines the proximity of nodes within the ring and also tells which nodes are faster. Cassandra nodes use this information to route read/write requests efficiently. We will discuss this in detail later.
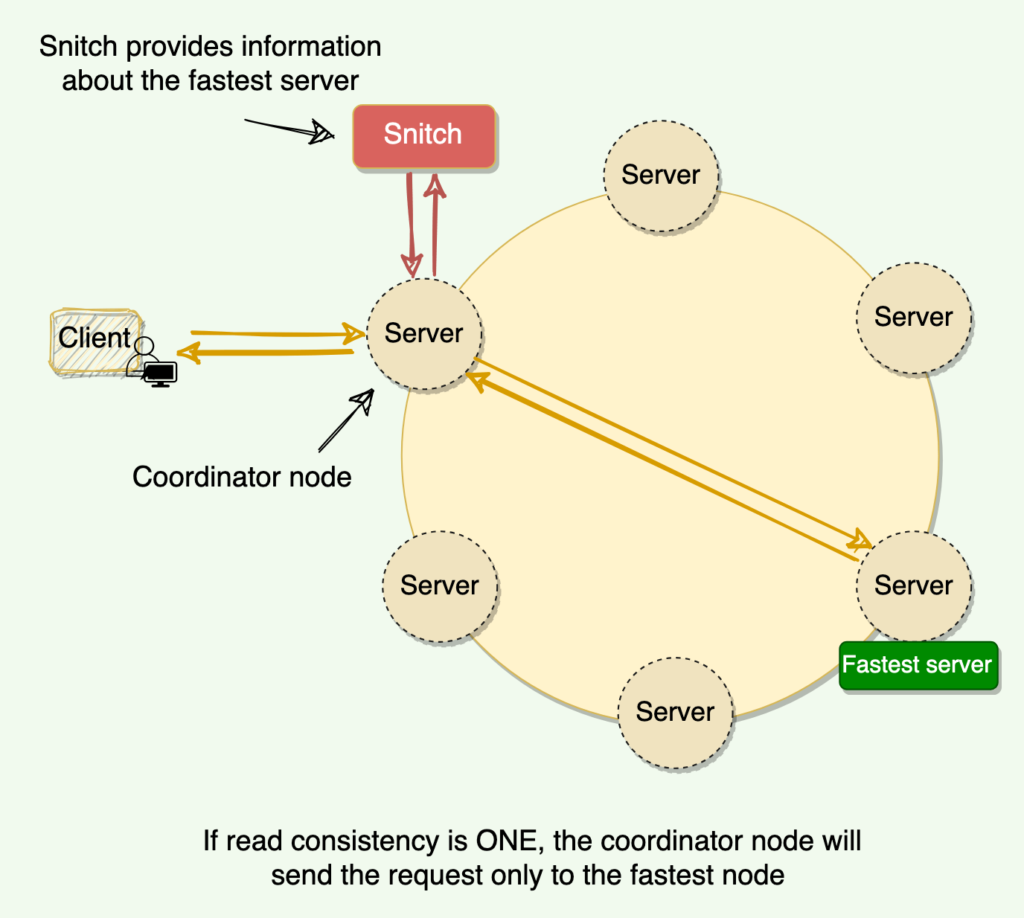
How does Cassandra perform a read operation? The coordinator always sends the read request to the fastest node. For example, for Quorum=2, the coordinator sends the request to the fastest node and the digest of the data from the second-fastest node. The digest is a checksum of the data and is used to save network bandwidth.
If the digest does not match, it means some replicas do not have the latest version of the data. In this case, the coordinator reads the data from all the replicas to determine the latest data. The coordinator then returns the latest data to the client and initiates a read repair request. The read repair operation pushes the newer version of data to nodes with the older version.
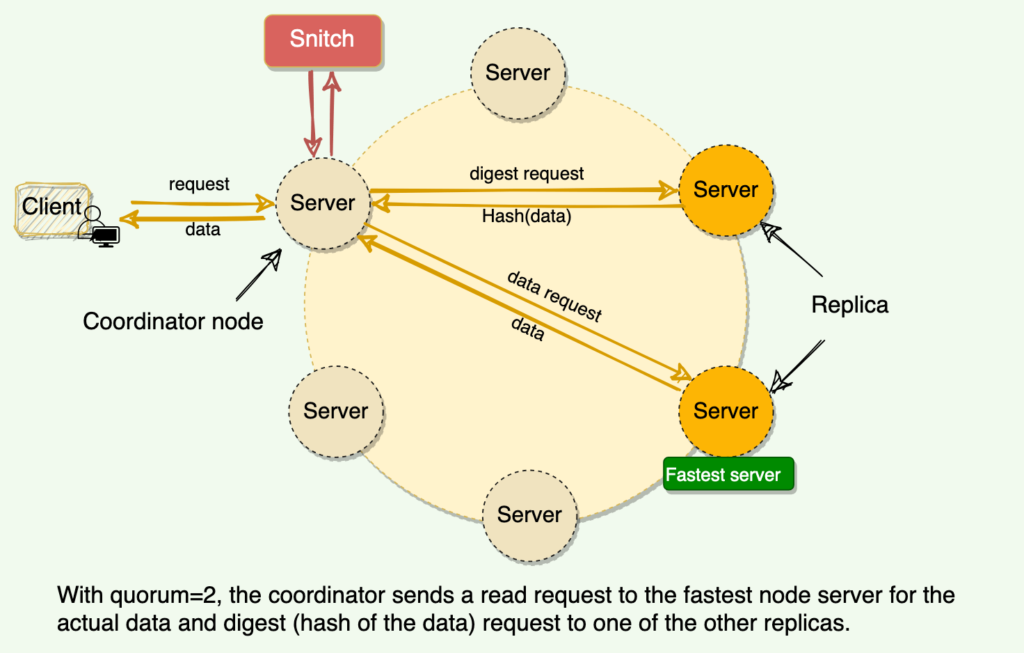
Read Repair Chance: When the read consistency level is less than ‘All,’ Cassandra performs a read repair probabilistically. By default, Cassandra tries to read repair 10% of all requests with DC local read repair. In this case, Cassandra immediately sends a response when the consistency level is met and performs the read repair asynchronously in the background.
Snitch
Snitch keeps track of the network topology of Cassandra nodes. It determines which data centers and racks nodes belong to. Cassandra uses this information to route requests efficiently. Here are the two main functions of a snitch in Cassandra:
- Snitch determines the proximity of nodes within the ring and also monitors the read latencies to avoid reading from nodes that have slowed down. Each node in Cassandra uses this information to route requests efficiently.
- Cassandra’s replication strategy uses the information provided by the Snitch to spread the replicas across the cluster intelligently. Cassandra will do its best by not having more than one replica on the same “rack”.
To understand Snitch’s role, let’s take the example of Cassandra’s read operation. Let’s assume that the client is performing a read with a quorum consistency level, and the data is replicated on five nodes. To support maximum read speed, Cassandra selects a single replica to query for the full object and asks for the digest of the data from two additional nodes in order to ensure that the latest version of the data is returned. The Snitch helps to identify the fastest replica, and Cassandra asks this replica for the full object.
In Cassandra, choosing the right consistency level is about balancing trade-offs based on the CAP theorem: Cassandra favors availability and partition tolerance but offers configurability in consistency.
That’s all about the Cassandra Consistency Levels in advanced system design concepts. If you have any queries or feedback, please write us email at contact@waytoeasylearn.com. Enjoy learning, Enjoy system design..!!