Cache Invalidation
In this tutorial, we are going to discuss about cache invalidation. Cache invalidation is a crucial concept in computer science, particularly in the realm of caching mechanisms used to optimize system performance.
Cache invalidation is a state where we push away the data from the cache memory when the data present is outdated so do we perform this operation of pushing back/flushing the cache otherwise this still data will result in inconsistency of data.
When cached data gets stale or inaccurate, cache invalidation is the process of removing or updating it. When the original data changes, the process of invalidating a cache involves deleting or updating cached data. It’s crucial because programs that rely on cached data may experience issues if it becomes outdated or erroneous over time.
Cache Invalidation Strategies
While caching is fantastic, it requires some maintenance to keep the cache coherent with the source of truth (e.g., database). If the data is modified in the database, it should be invalidated in the cache; if not, this can cause inconsistent application behavior. Solving this problem is known as cache invalidation; there are four main schemes that are used:
1. Write-through cache
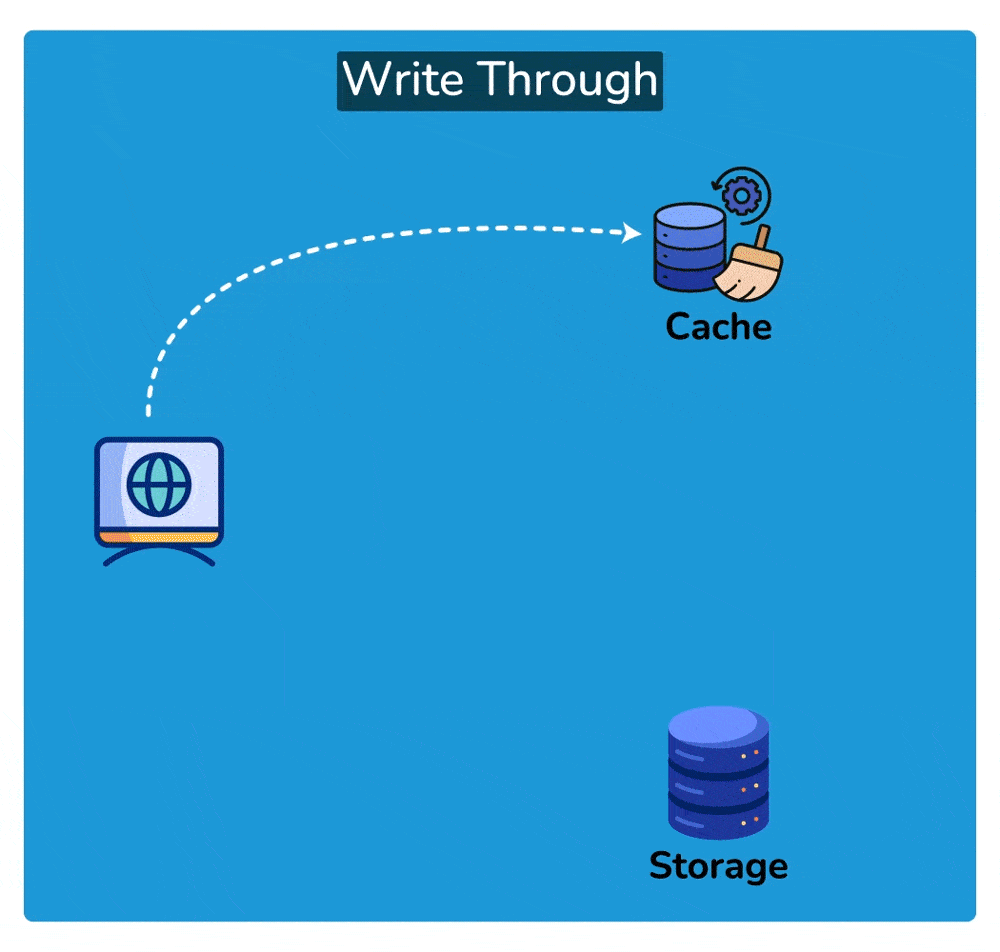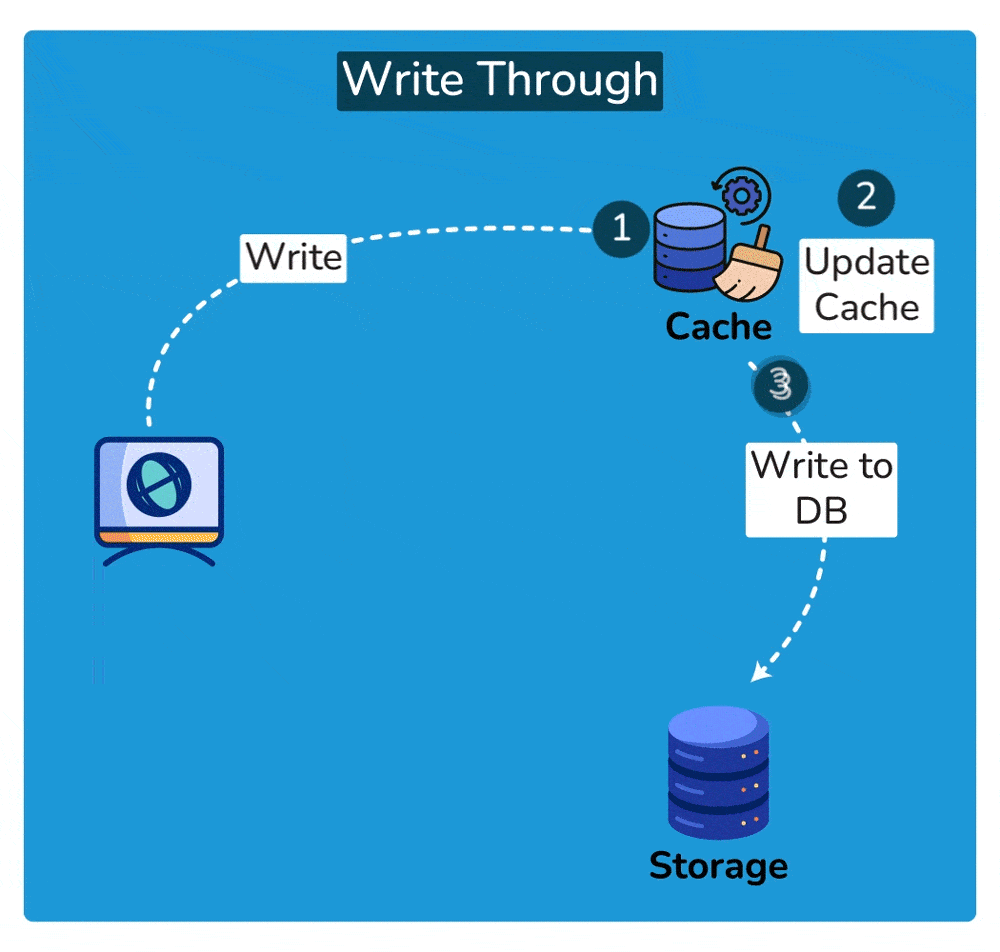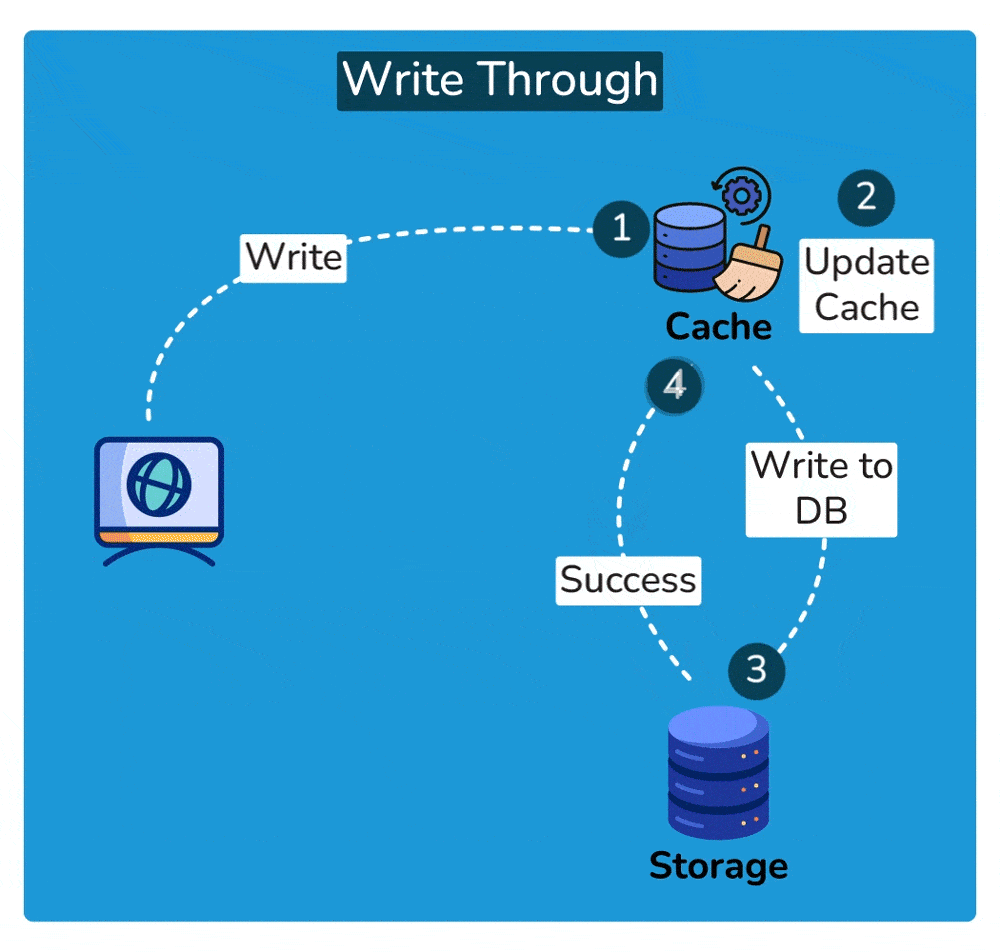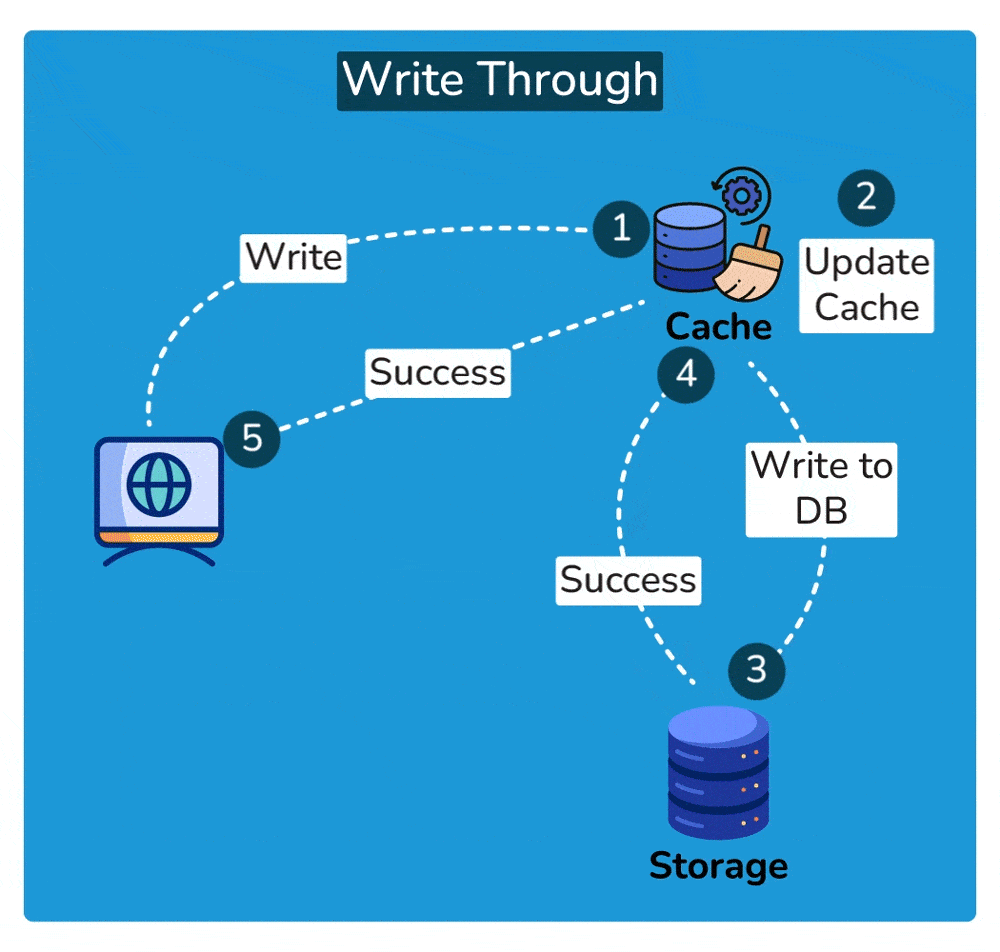
A write-through cache is a caching technique where every write operation (update, insertion, or deletion) to the cache is immediately mirrored or propagated to the underlying data storage, such as a database or file system, before the operation is considered complete. This ensures that the cached data and the underlying data storage remain synchronized at all times.
Here’s how write-through caching typically works:
- Write Operation: When a write operation is initiated, such as updating a data item, it is first applied to the cache.
- Propagation to Underlying Storage: After updating the cache, the write operation is immediately forwarded to the underlying data storage, such as a database. This ensures that the data in the cache and the data in the storage remain consistent.
- Completion of Write Operation: The write operation is considered complete only after it has been successfully applied to both the cache and the underlying storage. This ensures that any subsequent read operations retrieve the most up-to-date data.
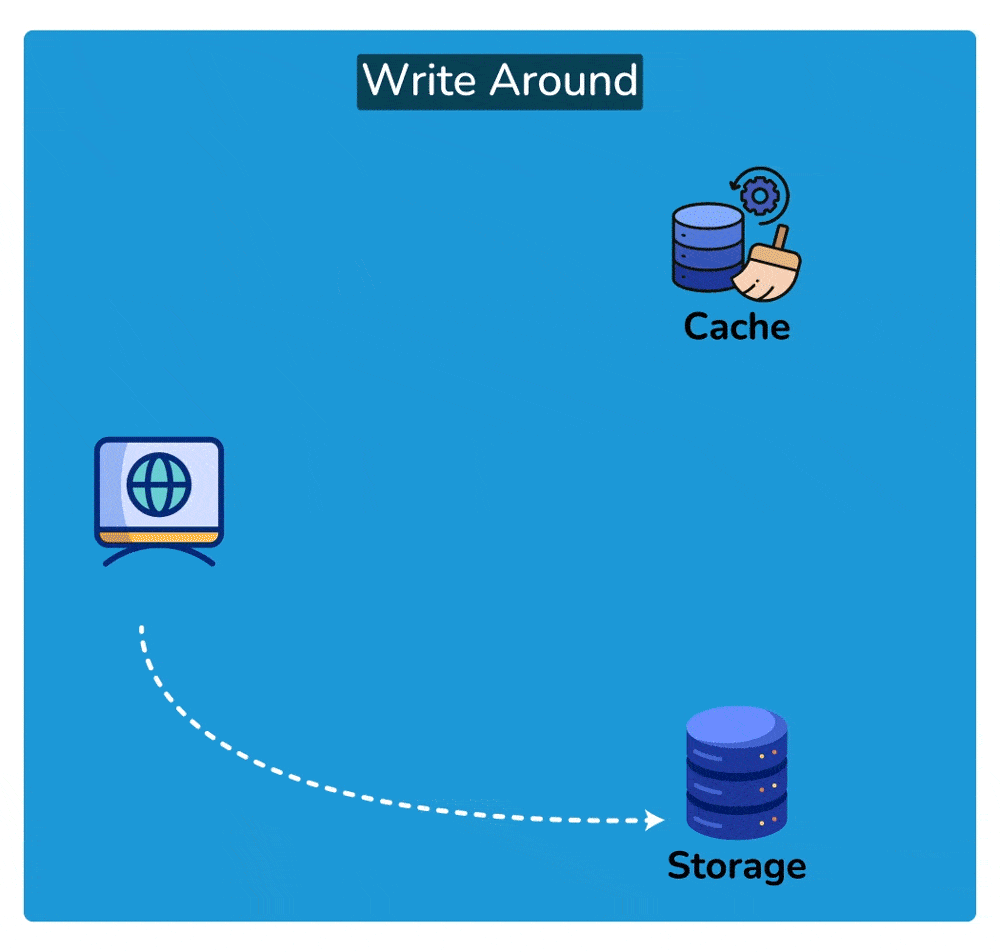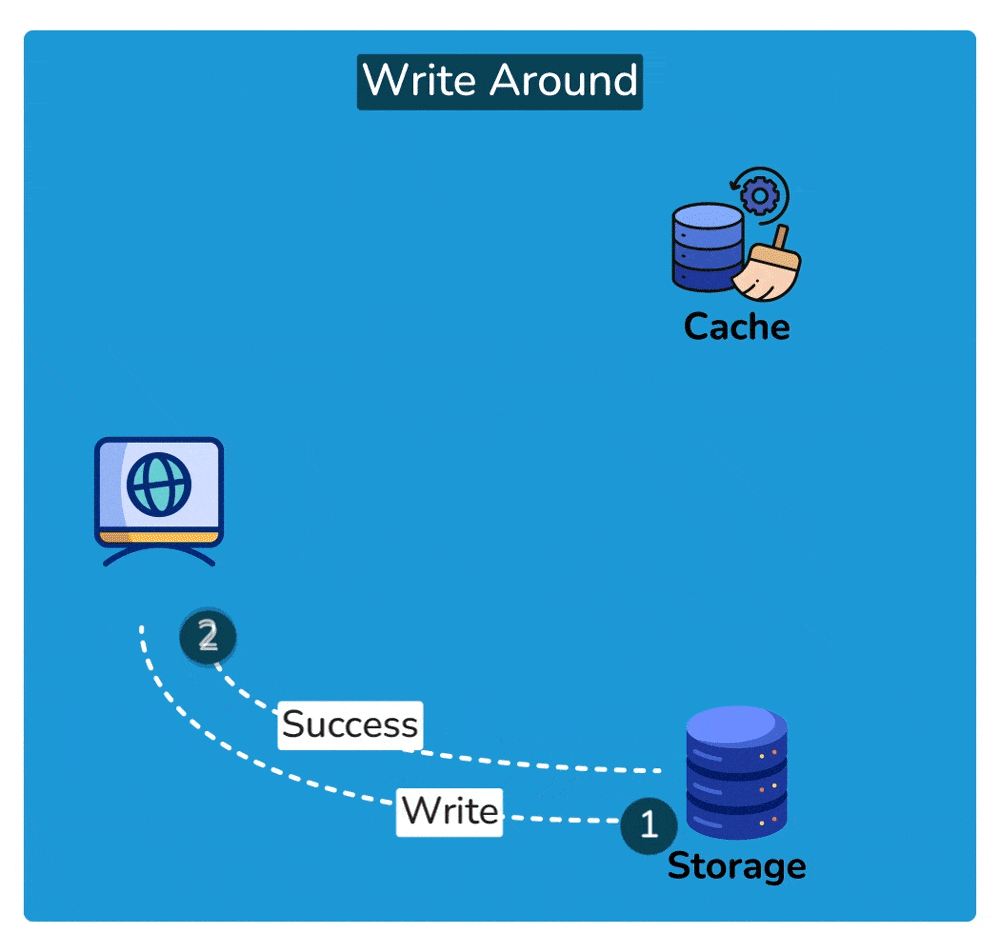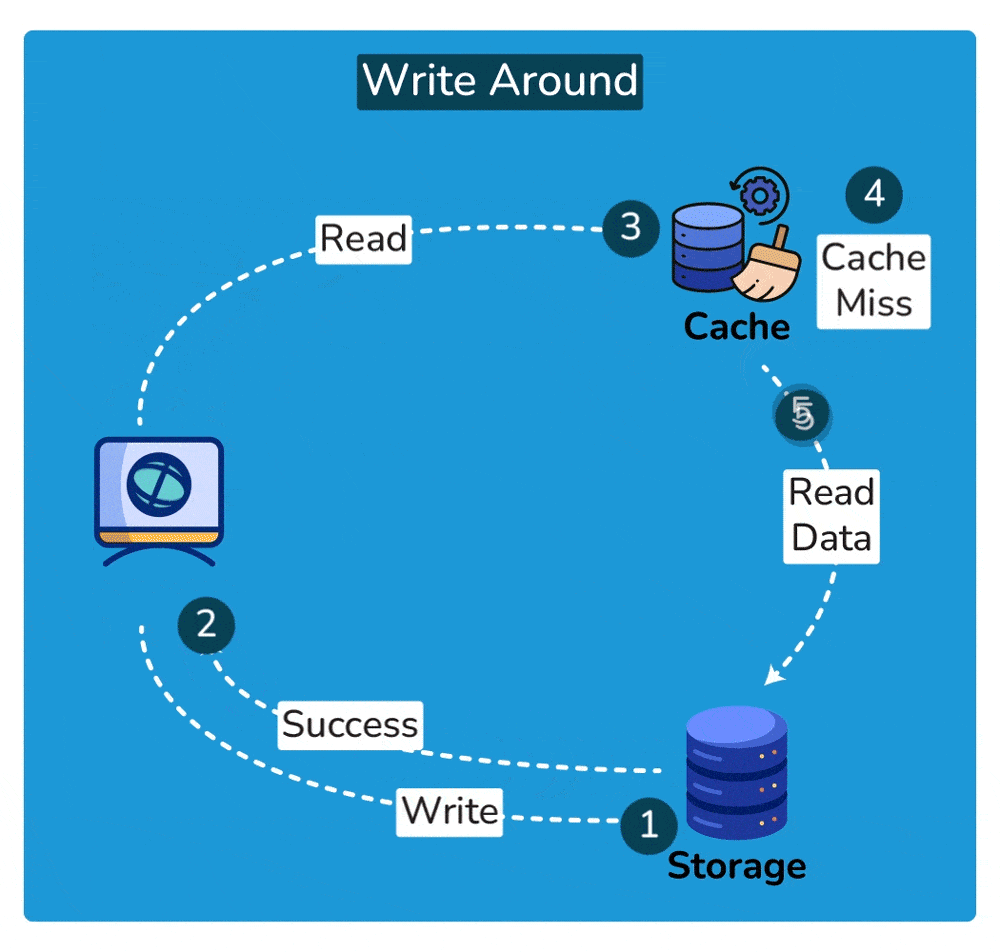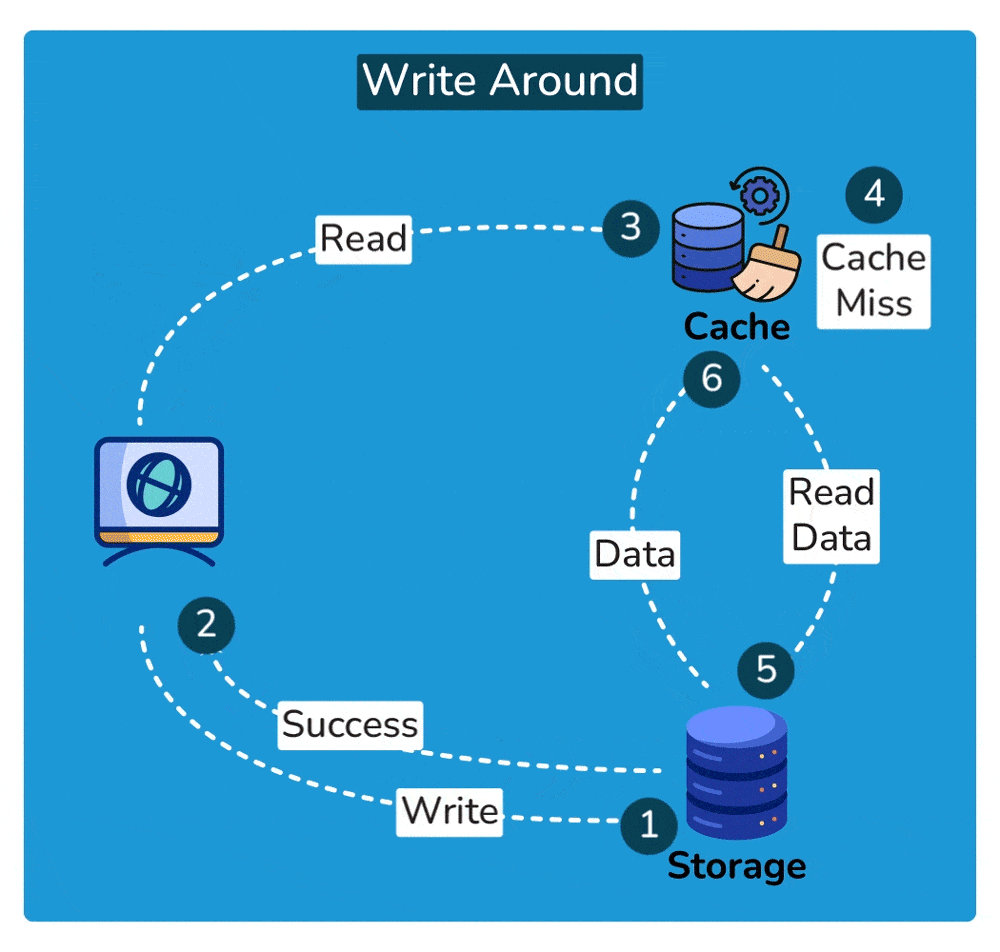
2. Write-around cache
A write-around cache is a caching technique where write operations bypass the cache and are written directly to the underlying storage. Unlike write-through caching, where write operations are immediately mirrored to both the cache and the storage, write-around caching does not store write operations in the cache.
Here’s how write-around caching typically works:
- Write Operation: When a write operation is initiated, such as updating a data item, it bypasses the cache entirely and is written directly to the underlying data storage, such as a database or disk.
- No Cache Update: Since the write operation does not touch the cache, the cache remains unchanged. This means that the data being written is not stored in the cache.
- Read Operation: Subsequent read operations for the same data item may result in cache misses since the data has not been cached. In this case, the data is fetched directly from the underlying storage.
3. Write-back cache
A write-back cache is a caching technique where write operations are initially written to the cache and then asynchronously written to the underlying storage at a later time. Unlike write-through caching, where write operations are immediately mirrored to both the cache and the storage, write-back caching delays the write to the underlying storage.
Here’s how write-back caching typically works:
- Write Operation: When a write operation is initiated, such as updating a data item, it is first applied to the cache.
- Delayed Write to Storage: Instead of immediately writing the updated data to the underlying storage, the write-back cache stores the updated data in the cache and acknowledges the write operation as complete. The write to the underlying storage is deferred until a later time, often during periods of low system activity.
- Cache Coherency Management: To ensure data consistency between the cache and the underlying storage, the write-back cache maintains metadata to track which cache lines have been modified but not yet written to the storage. This metadata is used to synchronize cache data with the storage when necessary.
- Write to Storage: Eventually, when the system is idle or during predefined intervals, the modified cache lines are flushed or written back to the underlying storage. This process updates the storage with the latest data from the cache.

4. Write-behind cache
It is quite similar to write-back cache. In this scheme, data is written to the cache and acknowledged to the application immediately, but it is not immediately written to the permanent storage. Instead, the write operation is deferred, and the data is eventually written to the permanent storage at a later time.
The main difference between write-back cache and write-behind cache is when the data is written to the permanent storage. In write-back caching, data is only written to the permanent storage when it is necessary for the cache to free up space, while in write-behind caching, data is written to the permanent storage at specified intervals.
5. Time Based Invalidation
Time-based invalidation is a cache invalidation strategy where cached data is considered valid for a predetermined period of time. After this period, the cached data is marked as invalid, and subsequent requests for the data trigger a refresh from the original data source.
Here’s how time-based invalidation typically works:
- Cache Initialization: When data is first retrieved from the original data source, it is cached along with a timestamp indicating when it was fetched.
- Validity Period: Each cached item is associated with a time-to-live (TTL) or expiration time, which specifies how long the data is considered valid. This TTL can be a fixed duration, such as 10 minutes, or dynamically determined based on factors like data volatility or business requirements.
- Cache Access: When a request is made for cached data, the cache checks the timestamp associated with the data item. If the current time exceeds the expiration time (i.e., the data has expired), the cache considers the data stale.
- Data Refresh: Upon detecting that the cached data has expired, the cache fetches fresh data from the original data source. The refreshed data replaces the stale data in the cache, and the timestamp is updated to reflect the new fetch time.
- Cache Hit: If the cached data is still valid (i.e., within its TTL), the cache returns the data directly to the requester without accessing the original data source, thus improving response time and reducing load on the backend systems.
6. Manual Invalidation
Manual invalidation is a cache invalidation strategy where developers or administrators manually trigger the invalidation of cached data when they know that the data has changed or become stale. This approach gives explicit control over when cached data should be refreshed and is particularly useful when changes to the data are infrequent or can be predicted.
Here’s how manual invalidation typically works:
- Change in Data: When data in the original data source is modified, updated, or deleted, developers or administrators are aware of the change through some form of monitoring, logging, or notification mechanism.
- Manual Invalidation: Upon detecting that the data has changed, developers or administrators initiate a manual invalidation process. This process involves identifying the affected cached data items and signaling the cache to invalidate or refresh those items.
- Cache Refresh: Once the cache receives the invalidation signal, it removes the stale data from the cache or marks it as invalid. Subsequent requests for the invalidated data trigger a refresh from the original data source, ensuring that users access the most up-to-date information.
Versioning
Versioning cache invalidation is a strategy where each cached item is associated with a version number or timestamp. When the data in the original source changes, the version identifier of the affected data is updated. Cached items are then invalidated based on a comparison between their version and the version of the latest data.
Here’s how versioning cache invalidation typically works:
- Data Versioning: Each data item in the original data source is assigned a version number or timestamp. This version reflects the state of the data at a particular point in time.
- Cache Initialization: When data is first retrieved from the original data source, it is cached along with its version identifier.
- Version Comparison: When subsequent requests for cached data are made, the cache checks the version identifier associated with the cached data against the version of the latest data in the original source.
- Invalidation Decision: If the version of the cached data is older than the version of the latest data, it indicates that the cached data is stale or outdated. In this case, the cached data is invalidated, and a fresh copy is fetched from the original data source.
- Cache Hit: If the version of the cached data matches or is newer than the version of the latest data, it indicates that the cached data is still valid. The cache returns the cached data directly to the requester without accessing the original data source, improving response time and reducing load on the backend systems.
Cache Invalidation Methods
Cache invalidation methods are strategies employed to ensure that cached data remains consistent with the original data source. Here are the famous cache invalidation methods:
Purge
The purge method removes cached content for a specific object, URL, or a set of URLs. It’s typically used when there is an update or change to the content and the cached version is no longer valid. When a purge request is received, the cached content is immediately removed, and the next request for the content will be served directly from the origin server.
Refresh
Fetches requested content from the origin server, even if cached content is available. When a refresh request is received, the cached content is updated with the latest version from the origin server, ensuring that the content is up-to-date. Unlike a purge, a refresh request doesn’t remove the existing cached content; instead, it updates it with the latest version.
Ban
The ban method invalidates cached content based on specific criteria, such as a URL pattern or header. When a ban request is received, any cached content that matches the specified criteria is immediately removed, and subsequent requests for the content will be served directly from the origin server.
Time-to-live (TTL) expiration
This method involves setting a time-to-live value for cached content, after which the content is considered stale and must be refreshed. When a request is received for the content, the cache checks the time-to-live value and serves the cached content only if the value hasn’t expired. If the value has expired, the cache fetches the latest version of the content from the origin server and caches it.
Stale-while-revalidate
This method is used in web browsers and CDNs to serve stale content from the cache while the content is being updated in the background. When a request is received for a piece of content, the cached version is immediately served to the user, and an asynchronous request is made to the origin server to fetch the latest version of the content. Once the latest version is available, the cached version is updated. This method ensures that the user is always served content quickly, even if the cached version is slightly outdated.
Choosing the right cache invalidation strategy depends on factors such as the nature of the data, the frequency of updates, performance requirements, and system architecture. A combination of these strategies may also be employed to address different caching scenarios within a system.
That’s all about the Cache Invalidation. If you have any queries or feedback, please write us email at contact@waytoeasylearn.com. Enjoy learning, Enjoy system design..!!