Apache HDFS follows Write Once – Read Many Philosophy. So, you can’t edit files already stored in HDFS. But, you can append new data by re-opening the file.
1. HDFS Write Architecture
Let us assume a situation where an HDFS client, wants to write a file named “ashok.txt” of size 250 MB. Assume that the system block size is configured for 128 MB (default). So, the client will be dividing the file “ashok.txt” into 2 blocks – one of 128 MB (Block A) and the other of 122 MB (block B). Now, the following protocol will be followed whenever the data is written into HDFS
1. At first, the HDFS client will reach out to the NameNode for a Write Request against the two blocks, say, Block A and Block B.
2. The NameNode will then grant the client the write permission and will provide the IP addresses of the DataNodes where the file blocks will be copied eventually.
3. The selection of IP addresses of DataNodes is purely randomized based on availability, replication factor and rack awareness.
4. Let’s say the replication factor is set to default i.e. 3. Therefore, for each block the NameNode will be providing the client a list of (3) IP addresses of DataNodes. The list will be unique for each block.
5. Suppose, the NameNode provided following lists of IP addresses to the client
- For Block A, list A = {IP of DataNode 1, IP of DataNode 4, IP of DataNode 6}
- For Block B, list B = {IP of DataNode 3, IP of DataNode 7, IP of DataNode 9}
6. Each block will be copied in three different DataNodes to maintain the replication factor consistent throughout the cluster.
7. Now the whole data copy process will happen in three stages.
- Set up of Pipeline
- Data streaming and replication
- Shutdown of Pipeline (Acknowledgement stage)
1. Set up of Pipeline
Before writing the blocks, the client confirms whether the DataNodes, present in each of the list of IPs, are ready to receive the data or not. In doing so, the client creates a pipeline for each of the blocks by connecting the individual DataNodes in the respective list for that block. Let us consider Block A. The list of DataNodes provided by the NameNode is:
For Block A, list A = {IP of DataNode 1, IP of DataNode 4, IP of DataNode 6}.
So, for block A, the client will be performing the following steps to create a pipeline
1. The client will choose the first DataNode in the list (DataNode IPs for Block A) which is DataNode 1 and will establish a TCP/IP connection.
2. The client will inform DataNode 1 to be ready to receive the block. It will also provide the IPs of next two DataNodes (4 and 6) to the DataNode 1 where the block is supposed to be replicated.
3. The DataNode 1 will connect to DataNode 4. The DataNode 1 will inform DataNode 4 to be ready to receive the block and will give it the IP of DataNode 6. Then, DataNode 4 will tell DataNode 6 to be ready for receiving the data.
4. Next, the acknowledgement of readiness will follow the reverse sequence, i.e. From the DataNode 6 to 4 and then to 1.
5. At last DataNode 1 will inform the client that all the DataNodes are ready and a pipeline will be formed between the client, DataNode 1, 4 and 6.
Now pipeline set up is complete and the client will finally begin the data copy or streaming process.
2. Data Streaming
After the pipeline has been created, now the client will push the data into the pipeline. Now, don’t forget that in HDFS, data is replicated based on replication factor. So, here Block A will be stored to three DataNodes as the assumed replication factor is 3. Moving ahead, the client will copy the block (A) to DataNode 1 only. The replication is always done by DataNodes sequentially. So, the following steps will take place during replication:
1. Once the block has been written to DataNode 1 by the client, DataNode 1 will connect to DataNode 4.
2. Then, DataNode 1 will push the block in the pipeline and data will be copied to DataNode 4.
3. Again, DataNode 4 will connect to DataNode 6 and will copy the last replica of the block.
3. Shutdown of Pipeline or Acknowledgement stage
Once the block has been copied into all the 3 DataNodes, a series of acknowledgements will take place to ensure the client and NameNode that the data has been written successfully. Then, the client will finally close the pipeline to end the TCP session.
The acknowledgement happens in the reverse sequence i.e. from DataNode 6 to 4 and then to 1. Finally, the DataNode 1 will push three acknowledgements (including its own) into the pipeline and send it to the client. The client will inform NameNode that data has been written successfully. The NameNode will update its metadata and the client will shut down the pipeline.
Similarly, Block B will also be copied into the DataNodes in parallel with Block A. So, the following things are to be noticed here:
1. The client will copy Block A and Block B to the first DataNode simultaneously.
2. Therefore, in our case, two pipelines will be formed for each of the block and all the process discussed above will happen in parallel in these two pipelines.
3. The client writes the block into the first DataNode and then the DataNodes will be replicating the block sequentially.
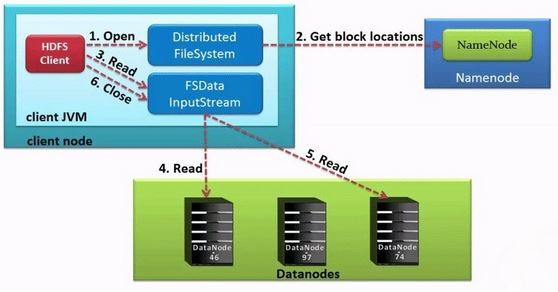
2. HDFS Read Architecture
HDFS Read architecture is comparatively easy to understand. Let’s take the above example again where the HDFS client wants to read the file “ashok.txt” now. Now, following steps will be taking place while reading the file:
1. First client will reach out to NameNode asking for the block metadata for the file “ashok.txt”.
2. The NameNode will return the list of DataNodes where each block (Block A and B) are stored.
3. After that client, will connect to the DataNodes where the blocks are stored.
4. The client starts reading data parallel from the DataNodes (Block A from DataNode 1 and Block B from DataNode 3).
5. Once the client gets all the required file blocks, it will combine these blocks to form a file.
While serving read request of the client, HDFS selects the replica which is closest to the client. This reduces the read latency and the bandwidth consumption. Therefore, that replica is selected which resides on the same rack as the reader node, if possible.
HDFS Read/Write Operation
1. Write Operation
1. Interaction of Client with NameNode
If the client has to create a file inside HDFS then he needs to interact with the NameNode (as NameNode is the centre-piece of the cluster which contains metadata). Namenode provides the address of all the slaves where the client can write its data. The client also gets a security token from the NameNode which they need to present to the slaves for authentication before writing the block. Below are the steps which client needs to perform in order to write data in HDFS:
To create a file client executes create () method on DistributedFileSystem. Now DistributedFileSystem interacts with the NameNode by making an RPC call for creating a new file having no blocks associated with it in the filesystem’s namespace. Various checks are executed by the NameNode in order to make sure that there is no such file, already present there and the client is authorized to create a new file.
If all this procedure gets the pass, then a record of the new file is created by the NameNode; otherwise, file creation fails and an IOException is thrown to the client. An FSDataOutputStream returns by the DistributedFileSystem for the client in order to start writing data to DataNode. Communication with DataNodes and client is handled by DFSOutputStream which is a part of FSDataOutputStream.
2. Interaction of client with Datanodes
After the user gets authenticated to create a new file in the filesystem namespace, Namenode will provide the location to write the blocks. Hence the client directly goes to the DataNodes and start writing the data blocks there. As in HDFS replicas of blocks are created on different nodes, hence when the client finishes with writing a block inside the slave, the slave then starts making replicas of a block on the other slaves. And in this way, multiple replicas of a block are created in different blocks. Minimum 3 copies of blocks are created in different slaves and after creating required replicas, it sends an acknowledgment to the client. In this manner, while writing data block a pipeline is created and data is replicated to desired value in the cluster.
Let’s understand the procedure in great details. Now when the client writes the data, they are split into the packets by the DFSOutputStream. These packets are written to an internal queue, called the data queue. The data queue is taken up by the DataStreamer. The main responsibility of DataStreamer is to ask the NameNode to properly allocate the new blocks on suitable DataNodes in order to store the replicas. List of DataNodes creates a pipeline, and here let us assume the default replication level is three; hence in the pipeline there are three nodes. The packets are streamed to the first DataNode on the pipeline by the DataStreamer, and DataStreamer stores the packet and this packet is then forwarded to the second DataNode in the pipeline.
In the same way, the packet is stored into the second DataNode and then it is forwarded to the third (and last) DataNode in the pipeline. An internal queue known as “ack queue” of packets that are waiting to be acknowledged by DataNodes is also maintained. A packet is only removed from the ack queue if it gets acknowledged by all the DataNodes in the pipeline. A client calls the close () method on the stream when it has finished writing data.
When executing the above method, all the remaining packets get flushed to the DataNode pipeline and before contacting the NameNode it waits for acknowledgments to signal that the file is complete. This is already known to the NameNode that which blocks the file is made up of, and hence before returning successfully it only has to wait for blocks to be minimally replicated.
2. Read Operation
Client interact with NameNode
As NameNode contains all the information regarding which block is stored on which particular slave in HDFS, which are the blocks for the specific file. Hence client needs to interact with the Namenode in order to get the address of the slaves where the blocks are actually stored. NameNode will provide the details of slaves which contain required blocks.
Let’s understand client and NameNode interaction in more details. To access the blocks stored in HDFS, a client initiates a request ‘open ()‘ method to the FileSystem object, which is a part of DistributedFileSystem. Now the FileSystem will interact with the NameNode using RPC (Remote Procedure Call), to get the location of the slaves which contains the blocks of the file requested by the client.
At this level, NameNode will check whether the client is authorized to access that file, if yes then it sends the information of the block locations. Also, it gives a security token to the client which they need to show to the slaves for authentication.
Client interact with DataNode
Now after receiving the address of slaves containing blocks, the client will directly interact with Slave to read the blocks. The data will flow directly from the slaves to the client (it will not flow via NameNode). The client reads the data block from multiple slaves in parallel.
Let’s understand client and NameNode interaction in more details. The client will send a read request to slaves via using the FSDataInputStream object. All the interactions between client and DataNode are managed by the DFSInputStream which is a part of client APIs. The client will show authentication token to slaves which were provided by NameNode. Now client will start reading the blocks using InputStream API, data will be transmitted continuously from DataNode and client. After reaching an end of a block, the connection is closed to the DataNode by the DFSInputStream.
Read operation is highly optimized, as it does not involve NameNode for actual data read, otherwise NameNode would have become the bottleneck. Due to distributed parallel read mechanism, thousands of clients can read the data directly from DataNodes very efficiently.
HDFS follow Write Once Read many models. So, we cannot edit files already stored in HDFS, but we can append data by reopening the file. In Read-Write operation client first, interact with the NameNode. NameNode provides privileges so, the client can easily read and write data blocks into/from the respective DataNodes.
Hadoop HDFS (In Depth) Data Read and Write Operations
HDFS – Hadoop Distributed File System is the storage layer of Hadoop. It is most reliable storage system on the planet. HDFS works in master-slave fashion, NameNode is the master daemon which runs on the master node, DataNode is the slave daemon which runs on the slave node. Hadoop HDFS Data Write Operation.
To write a file in HDFS, a client needs to interact with master i.e. NameNode (master). Now NameNode provides the address of the DataNodes (slaves) on which client will start writing the data. Client directly writes data on the DataNodes, now DataNode will create data write pipeline.
The first datanode will copy the block to another DataNode, which intern copy it to the third DataNode. Once it creates the replicas of blocks, it sends back the acknowledgment.
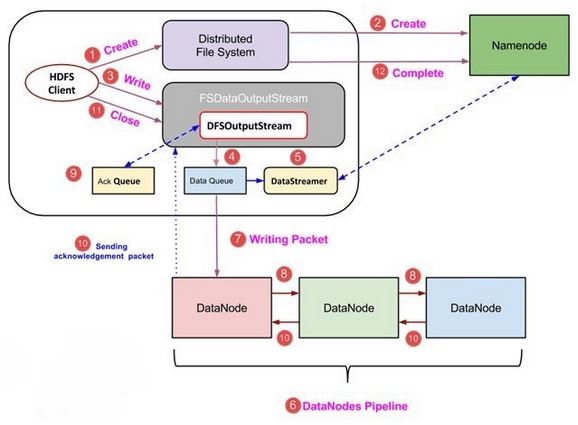
HDFS Data Write Pipeline Workflow
Step 1: The HDFS client sends a create request on DistributedFileSystem APIs.
Step 2: DistributedFileSystem makes an RPC call to the namenode to create a new file in the file system’s namespace. The namenode performs various checks to make sure that the file doesn’t already exist and that the client has the permissions to create the file. When these checks pass, then only the namenode makes a record of the new file; otherwise, file creation fails and the client is thrown an IOException.
Step 3: The DistributedFileSystem returns a FSDataOutputStream for the client to start writing data to. As the client writes data, DFSOutputStream splits it into packets, which it writes to an internal queue, called the data queue. The data queue is consumed by the DataStreamer, which is responsible for asking the namenode to allocate new blocks by picking a list of suitable DataNodes to store the replicas.
Step 4: The list of DataNodes form a pipeline, and here we’ll assume the replication level is three, so there are three nodes in the pipeline. The DataStreamer streams the packets to the first DataNode in the pipeline, which stores the packet and forwards it to the second DataNode in the pipeline. Similarly, the second DataNode stores the packet and forwards it to the third (and last) DataNode in the pipeline.
Step 5: DFSOutputStream also maintains an internal queue of packets that are waiting to be acknowledged by DataNodes, called the Ack Queue. A packet is removed from the ack queue only when it has been acknowledged by the DataNodes in the pipeline. DataNodes sends the acknowledgment once required replicas are created (3 by default). Similarly, all the blocks are stored and replicated on the different DataNodes, the data blocks are copied in parallel.
Step 6: When the client has finished writing data, it calls close () on the stream.
Step 7: This action flushes all the remaining packets to the DataNode pipeline and waits for acknowledgments before contacting the NameNode to signal that the file is complete. The NameNode already knows which blocks the file is made up of, so it only has to wait for blocks to be minimally replicated before returning successfully.
We can summarize the HDFS data write operation from the following diagram

Hadoop HDFS Data Read Operation
To read a file from HDFS, a client needs to interact with NameNode (master) as NameNode is the centerpiece of Hadoop cluster (it stores all the metadata i.e. data about the data). Now NameNode checks for required privileges, if the client has sufficient privileges then NameNode provides the address of the slaves where a file is stored. Now client will interact directly with the respective DataNodes to read the data blocks.
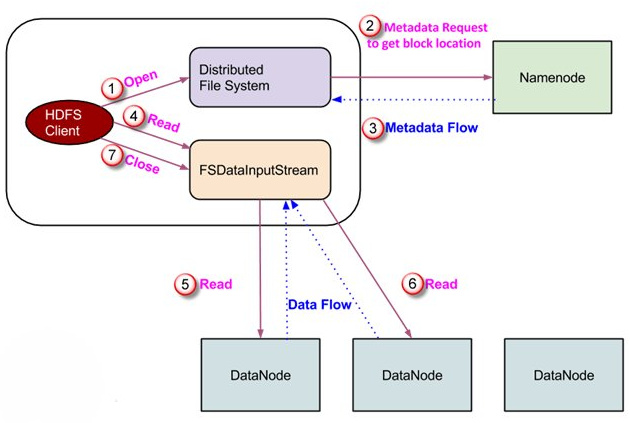
HDFS File Read Workflow
Step 1: Client opens the file it wishes to read by calling open() on the FileSystem object, which for HDFS is an instance of DistributedFileSystem.
Step 2: DistributedFileSystem calls the NameNode using RPC to determine the locations of the blocks for the first few blocks in the file. For each block, the NameNode returns the addresses of the DataNodes that have a copy of that block and DataNode are sorted according to their proximity to the client.
Step 3: DistributedFileSystem returns a FSDataInputStream to the client for it to read data from. FSDataInputStream, thus, wraps the DFSInputStream which manages the DataNode and NameNode I/O. Client calls read () on the stream. DFSInputStream which has stored the DataNode addresses then connects to the closest DataNode for the first block in the file.
Step 4: Data is streamed from the DataNode back to the client, as a result client can call read () repeatedly on the stream. When the block ends, DFSInputStream will close the connection to the DataNode and then finds the best DataNode for the next block.
Step 5: If the DFSInputStream encounters an error while communicating with a DataNode, it will try the next closest one for that block. It will also remember DataNodes that have failed so that it doesn’t needlessly retry them for later blocks. The DFSInputStream also verifies checksums for the data transferred to it from the DataNode. If it finds a corrupt block, it reports this to the NameNode before the DFSInputStream attempts to read a replica of the block from another DataNode.
Step 6: When the client has finished reading the data, it calls close () on the stream.
We can summarize the HDFS data read operation from the following diagram