Asynchronous Programming
In this tutorial, we are going to discuss about the Asynchronous Programming. We developers live in an industry of buzzwords, technologies, and practices hype cycles.
Asynchronous and reactive are important topics in modern applications, and my goal with this tutorial is to help developers understand the core concepts behind these terms, gain practical experience, and recognize when there are benefits to these approaches. We will use Eclipse Vert.x, a toolkit for writing asynchronous applications that has the added benefit of providing solutions for the different definitions of what “reactive” means.
Ensuring that you understand the concepts is a priority for me in this tutorial. While I want to give you a solid understanding of how to write Vert.x applications, I also want to make sure that you can translate the skills you learn here to other similar and possibly competing technologies, now or five years down the road.
Being distributed and networked is the norm
It was common 20 years ago to deploy business applications that could perform all operations while running isolated on a single machine. Such applications typically exhibited a graphical user interface, and they had local databases or custom file management for storing data. This is, of course, a gross exaggeration, as networking was already in use, and business applications could take advantage of database servers over the network, networked file storage, and various remote code operations.
Today, an application is more naturally exposed to end users through web and mobile interfaces. This naturally brings the network into play, and hence distributed systems. Also, service-oriented architectures allow the reuse of some functionality by issuing requests to other services, possibly controlled by a third-party provider. Examples would be delegating authentication in a consumer application to popular account providers like Google, Facebook, or Twitter, or delegating payment processing to Stripe or PayPal.
Not living on an isolated island
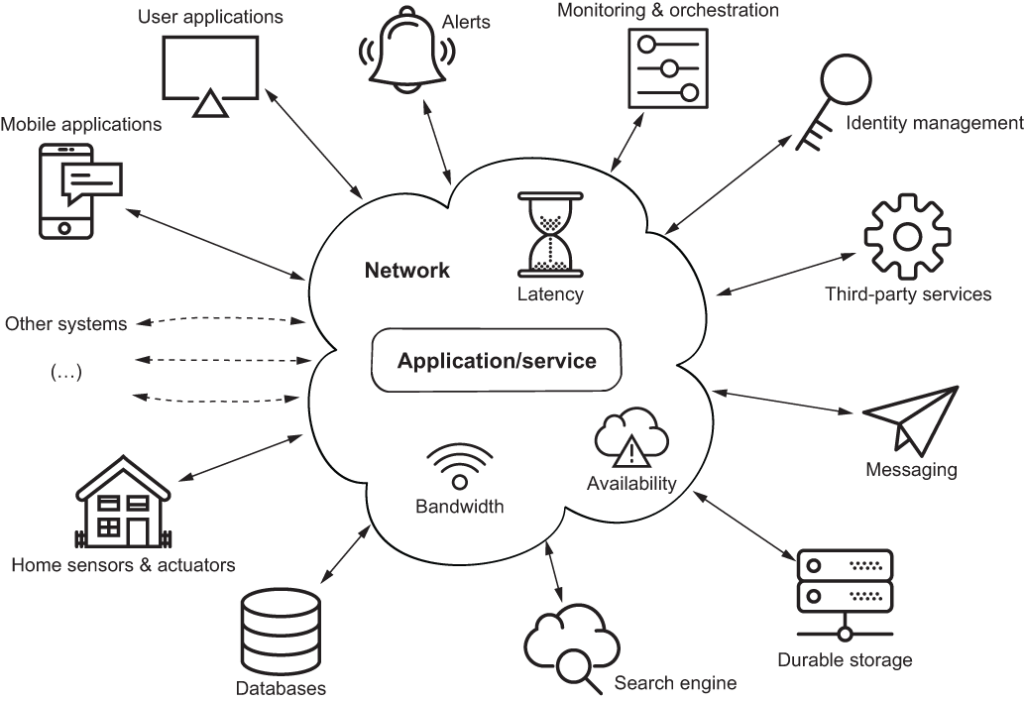
The above image is a fictional depiction of what a modern application is: a set of networked services interacting with each other. Here are some of these networked services:
- A database like PostgreSQL or MongoDB stores data.
- A search engine like Elasticsearch allows finding information that was previously indexed, such as products in a catalog.
- A durable storage service like Amazon S3 provides persistent and replicated data storage of documents.
- A messaging service can be
- An identity management service like Keycloak provides authentication and role management for user and service interactions.
- Monitoring with libraries like Micrometer exposes health statuses, metrics, and logs so that external orchestration tools can maintain proper quality of service, possibly by starting new service instances or killing existing ones when they fail.
Later in this tutorial you will see examples of typical services such as API endpoints, stream processors, and edge services. The preceding list is not exhaustive, of course, but the key point is that services rarely live in isolation, as they need to talk to other services over the network to function.
There is no free lunch on the network
The network is exactly where a number of things may go wrong in computing:
- The bandwidth can fluctuate a lot, so data-intensive interactions between services may suffer. Not all services can enjoy fast bandwidth inside the same data center, and even so, it remains slower than communications between processes on the same machine.
- The latency fluctuates a lot, and because services need to talk to services that talk to additional services to process a given request, all network-induced latency adds to the overall request-processing times.
- Availability should not be taken for granted: Networks fail. Routers fail. Proxies fail. Sometimes someone runs into a network cable and disconnects it. When the network fails, a service that sends a request to another service may not be able to determine if it is the other service or the network that is down.
In essence, modern applications are made of distributed and networked services. They are accessed over networks that themselves introduce problems, and each service needs to maintain several incoming and outgoing connections.
The simplicity of blocking APIs
Services need to manage connections to other services and requesters. The traditional and widespread model for managing concurrent network connections is to allocate a thread for each connection. This is the model in many technologies, such as Servlets in Jakarta EE (before additions in version 3), Spring Framework (before additions in version 5), Ruby on Rails, Python Flask, and many more. This model has the advantage of simplicity, as it is synchronous.
Let’s look at an example where a TCP server echoes input text back to the client until it sees a /quit terminal input. The code in the following listing provides the TCP server implementation. It is a classical use of the java.io package that provides synchronous I/O APIs.
package com.ashok.vertx;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.net.InetSocketAddress;
import java.net.ServerSocket;
import java.net.Socket;
/**
*
* @author ashok.mariyala
*
*/
public class SynchronousEcho {
public static void main(String[] args) throws Throwable {
try (ServerSocket server = new ServerSocket();) {
server.bind(new InetSocketAddress(5555));
while (true) {
Socket socket = server.accept();
new Thread(clientHandler(socket)).start();
}
}
}
private static Runnable clientHandler(Socket socket) {
return () -> {
try (BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
PrintWriter writer = new PrintWriter(new OutputStreamWriter(socket.getOutputStream()))) {
String line = "";
while (!"/quit".equals(line)) {
line = reader.readLine();
System.out.println("~ " + line);
writer.write(line + "\n");
writer.flush();
}
} catch (IOException e) {
e.printStackTrace();
}
};
}
}Once we run the above program, By using the netcat command-line tool, we can send and receive text.
$ netcat localhost 5555
Hello, waytoeasylearn visitors, welcome to the vertex tutorials
Hello, waytoeasylearn visitors, welcome to the vertex tutorials
How are you
How are you
/quit
/quit
In the above result Line 2, 4 and 6 lines are the user input on the command line and 3,5, and 7 line is sent by the TCP server.
On the server side, we can see the following trace.
~ Hello, waytoeasylearn visitors, welcome to the vertex tutorials
~ How are you
~ /quit- The main application thread plays the role of an accepting thread, as it receives socket objects for all new connections. The operation blocks when no connection is pending. A new thread is allocated for each connection.
- Reading from a socket may block the thread allocated to the connection, such as when insufficient data is being read.
- Writing to a socket may also block, such as until the underlying TCP buffer data has been sent over the network.
The server uses the main thread for accepting connections, and each connection is allocated a new thread for processing I/O. The I/O operations are synchronous, so threads may block on I/O operations.
Blocking APIs waste resources, increase costs
The main problem with the above code is that it allocates a new thread for each incoming connection, and threads are anything but cheap resources. A thread needs memory, and the more threads you have, the more you put pressure on the operating system kernel scheduler, as it needs to give CPU time to the threads. We could improve the above code by using a thread pool to reuse threads after a connection has been closed, but we still need n threads for n connections at any given point in time.
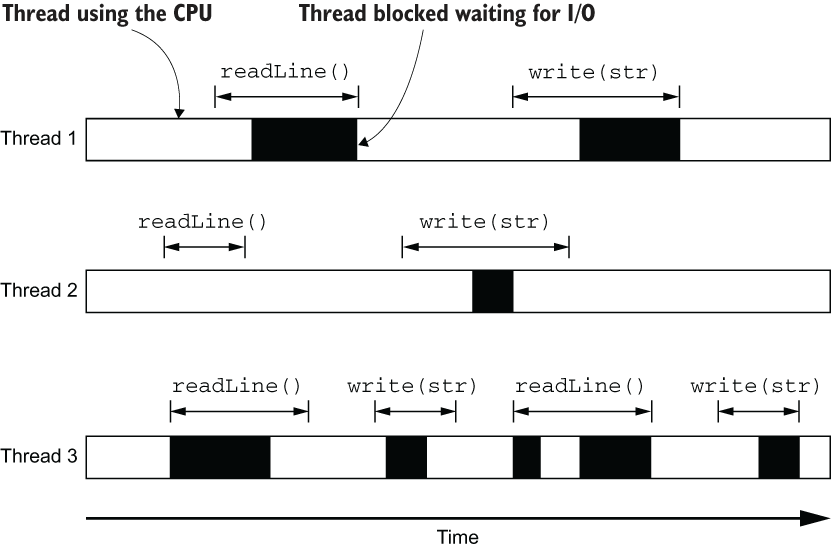
This is illustrated in above image, where you can see the CPU usage over time of three threads for three concurrent network connections. Input/output operations such as readLine and write may block the thread, meaning that it is being parked by the operating system. This happens for two reasons:
- A read operation may be waiting for data to arrive from the network.
- A write operation may have to wait for buffers to be drained if they are full from a previous write operation.
A modern operating system can properly deal with a few thousand concurrent threads. Not every networked service will face loads with so many concurrent requests, but this model quickly shows its limits when we are talking about tens of thousands of concurrent connections.
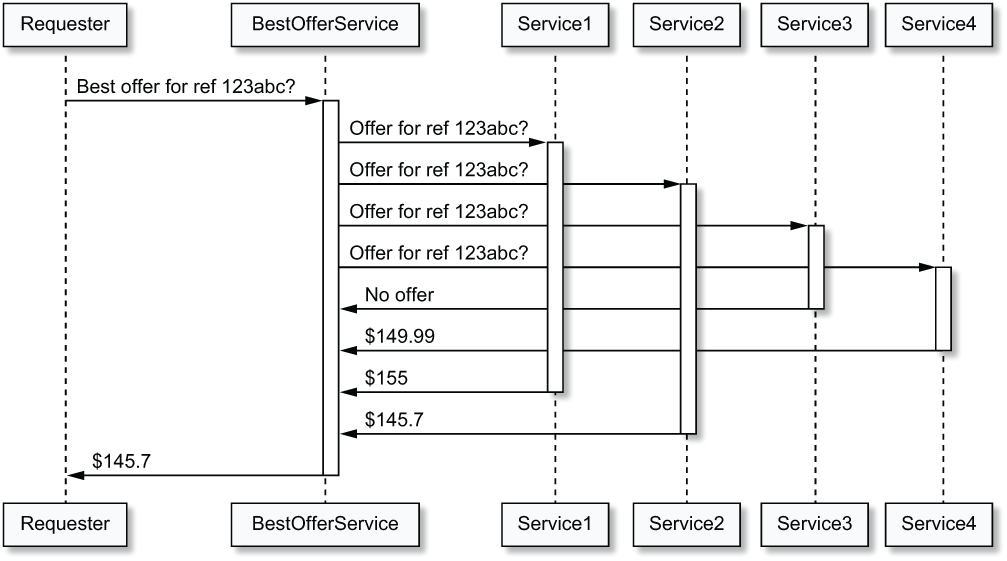
It is also important to recall that we often need more threads than incoming network connections. To take a concrete example, suppose that we have an HTTP service that offers the best price for a given product, which it does by requesting prices from four other HTTP services, as illustrated in the above image. This type of service is often called an edge service or an API gateway. Requesting each service in sequence and then selecting the lowest price would render our service very slow, as each request adds to our own service’s latency. The efficient way is to start four concurrent requests from our service, and then wait and gather their responses. This translates to starting four more threads; if we had 1,000 concurrent network requests, we might be using up to 5,000 threads in the worst naive case, where all requests need to be processed at the same time and we don’t use thread pooling or maintain persistent connections from the edge service to the requested services.
Last, but not least, applications are often deployed to containerized or virtualized environments. This means that applications may not see all the available CPU cores, and their allocated CPU time may be limited. Available memory for processes may also be restricted, so having too many threads also eats into the memory budget. Such applications have to share CPU resources with other applications, so if all applications use blocking I/O APIs, there can quickly be too many threads to manage and schedule, which requires starting more server/container instances as traffic ramps up. This translates directly to increased operating costs.
Asynchronous programming with non-blocking I/O
Instead of waiting for I/O operations to complete, we can shift to non-blocking I/O. You may have already sampled this with the select function in C.
The idea behind non-blocking I/O is to request a (blocking) operation, and move on to doing other tasks until the operation result is ready. For example a non-blocking read may ask for up to 256 bytes over a network socket, and the execution thread does other things (like dealing with another connection) until data has been put into the buffers, ready for consumption in memory. In this model, many concurrent connections can be multiplexed on a single thread, as network latency typically exceeds the CPU time it takes to read incoming bytes.
Java has long had the java.nio (Java NIO) package, which offers non-blocking I/O APIs over files and networks.
t is also important to note that like most JDK APIs, java.nio focuses solely on what it does (here, I/O APIs). It does not provide higher-level protocol-specific helpers, like for writing HTTP clients and servers. Also, java.nio does not prescribe a threading model, which is still important to properly utilize CPU cores, nor does it handle asynchronous I/O events or articulate the application processing logic.
This is why, in practice, developers rarely deal with Java NIO. Networking libraries like Netty and Apache MINA solve the shortcomings of Java NIO, and many toolkits and frameworks are built on top of them. As you will soon discover, Eclipse Vert.x is one of them.
Multiplexing event-driven processing: The case of the event loop
A popular threading model for processing asynchronous events is that of the event loop. Instead of polling for events that may have arrived, as we did in the previous Java NIO example, events are pushed to an event loop.
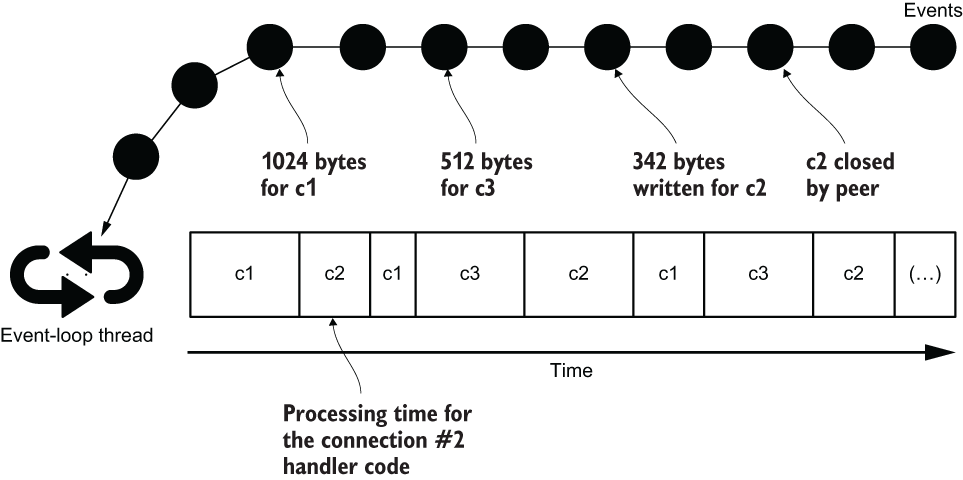
As you can see in the above picture, events are queued as they arrive. They can be I/O events, such as data being ready for consumption or a buffer having been fully written to a socket. They can also be any other event, such as a timer firing. A single thread is assigned to an event loop, and processing events shouldn’t perform any blocking or long-running operation. Otherwise, the thread blocks, defeating the purpose of using an event loop.
Event loops are quite popular: JavaScript code running in web browsers runs on top of an event loop. Many graphical interface toolkits, such as Java Swing, also have an event loop.
What is a reactive system?
So far we have discussed how to do the following:
- Leverage asynchronous programming and non-blocking I/O to handle more concurrent connections and use less threads
- Use one threading model for asynchronous event processing (the event loop)
By combining these two techniques, we can build scalable and resource-efficient applications. Let’s now discuss what a reactive system is and how it goes beyond “just” asynchronous programming.
The four properties of reactive systems are exposed in The Reactive Manifesto: responsive, resilient, elastic, and message-driven (www.reactivemanifesto.org/). We are not going to paraphrase the manifesto in this book, so here is a brief take on what these properties are about:
- Elastic –Elasticity is the ability for the application to work with a variable number of instances. This is useful, as elasticity allows the app to respond to traffic spikes by starting new instances and load-balancing traffic across instances. This has an interesting impact on the code design, as shared state across instances needs to be well identified and limited (e.g., server-side web sessions). It is useful for instances to report metrics, so that an orchestrator can decide when to start or stop instances based on both network traffic and reported metrics.
- Resilient –Resiliency is partially the flip side of elasticity. When one instance crashes in a group of elastic instances, resiliency is naturally achieved by redirecting traffic to other instances, and a new instance can be started if necessary. That being said, there is more to resiliency. When an instance cannot fulfill a request due to some conditions, it still tries to answer in degraded mode. Depending on the application domain, it may be possible to respond with older cached values, or even to respond with empty or default data. It may also be possible to forward a request to some other, non-error instance. In the worst case, an instance can respond with an error, but in a timely fashion.
- Responsive –Responsivity is the result of combining elasticity and resiliency. Consistent response times provide strong service-level agreement guarantees. This is achieved both thanks to the ability to start new instances if need be (to keep response times acceptable), and also because instances still respond quickly when errors arise. It is important to note that responsivity is not possible if one component relies on a non-scalable resource, like a single central database. Indeed, starting more instances does not solve the problem if they all issue requests to one resource that is quickly going to be overloaded.
- Message-driven –Using asynchronous message passing rather than blocking paradigms like remote procedure calls is the key enabler of elasticity and resiliency, which lead to responsiveness. This also enables messages to be dispatched to more instances (making the system elastic) and controls the flow between message producers and message consumers (this is back-pressure, and we will explore it later in this book).
A reactive system exhibits these four properties, which make for dependable and resource-efficient systems.
That’s all about the Asynchronous Programming brief overview. If you have any queries or feedback, please write us email at contact@waytoeasylearn.com.